| # Install on Terminal of MacOS #pip3 install -U numpy #pip3 install -U scipy #pip3 install -U pandas #pip3 install -U matplotlib |
1_MacOS_Terminal.txt
| ########## Run Terminal on MacOS and execute ### TO UPDATE cd "YOUR_WORKING_DIRECTORY" |
Python files
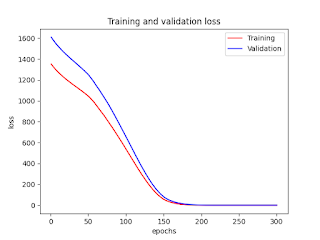
| ########## Python Statistics Fundamentals: How to Describe Your Data ########## # # # Reference: # # Python Statistics Fundamentals: How to Describe Your Data # by Mirko Stojiljkovic # https://realpython.com/python-statistics/ ##### Understanding Descriptive Statistics ##### Choosing Python Statistics Libraries # # - Python’s statistics is a built-in Python library for descriptive statistics. You can use it if your datasets are not too large or if you can’t rely on importing other libraries. # - NumPy is a third-party library for numerical computing, optimized for working with single- and multi-dimensional arrays. Its primary type is the array type called ndarray. This library contains many routines for statistical analysis. # - SciPy is a third-party library for scientific computing based on NumPy. It offers additional functionality compared to NumPy, including scipy.stats for statistical analysis. # - Pandas is a third-party library for numerical computing based on NumPy. It excels in handling labeled one-dimensional (1D) data with Series objects and two-dimensional (2D) data with DataFrame objects. # - Matplotlib is a third-party library for data visualization. It works well in combination with NumPy, SciPy, and Pandas. ##### Getting Started With Python Statistics Libraries ##### Calculating Descriptive Statistics # import import math import statistics import numpy as np import scipy.stats import pandas as pd #import matplotlib.pyplot as plt x = [8.0, 1, 2.5, 4, 28.0] x_with_nan = [8.0, 1, 2.5, math.nan, 4, 28.0] #x print(x) #[8.0, 1, 2.5, 4, 28.0] #x_with_nan print(x_with_nan) #[8.0, 1, 2.5, nan, 4, 28.0] #Note: How do you get a nan value? # #In Python, you can use any of the following: # #float('nan') #math.nan #np.nan # #You can use all of these functions interchangeably: # #math.isnan(np.nan), np.isnan(math.nan) print(math.isnan(np.nan), np.isnan(math.nan)) #(True, True) # #math.isnan(y_with_nan[3]), np.isnan(y_with_nan[3]) #print(math.isnan(y_with_nan[3]), np.isnan(y_with_nan[3])) print(math.isnan(x_with_nan[3]), np.isnan(x_with_nan[3])) #(True, True) # #You can see that the functions are all equivalent. However, please keep in mind that comparing two nan values for equality returns False. In other words, math.nan == math.nan is False! #print(math.isnan(float('nan')), math.isnan(math.nan), math.isnan(np.nan)) #(True, True, True) #print(np.isnan(float('nan')), np.isnan(math.nan), np.isnan(np.nan)) #(True, True, True) #Now, create np.ndarray and pd.Series objects that correspond to x and x_with_nan: # y, y_with_nan = np.array(x), np.array(x_with_nan) #NumPy arrays z, z_with_nan = pd.Series(x), pd.Series(x_with_nan) #Pandas Series #y print(y) #[ 8. 1. 2.5 4. 28. ] #y_with_nan print(y_with_nan) #[ 8. 1. 2.5 nan 4. 28. ] #z print(z) #0 8.0 #1 1.0 #2 2.5 #3 4.0 #4 28.0 #dtype: float64 # #z_with_nan print(z_with_nan) #0 8.0 #1 1.0 #2 2.5 #3 NaN #4 4.0 #5 28.0 #dtype: float64 # #You can optionally specify a label for each value in z and z_with_nan. #Note: Although you’ll use lists throughout this tutorial, please keep in mind that, in most cases, you can use tuples in the same way. ### Measures of Central Tendency ### Mean mean_ = sum(x) / len(x) #mean_ print(mean_) #8.7 mean_ = statistics.mean(x) #mean_ print(mean_) #8.7 mean_ = statistics.fmean(x) #fmean() is introduced in Python 3.8 as a faster alternative to mean(). It always returns a floating-point number. #mean_ print(mean_) #8.7 #However, if there are nan values among your data, then statistics.mean() and statistics.fmean() will return nan as the output: mean_ = statistics.mean(x_with_nan) #mean_ print(mean_) #nan mean_ = statistics.fmean(x_with_nan) #mean_ print(mean_) #nan #print(sum(x_with_nan)) #nan #If you use NumPy, then you can get the mean with np.mean(): mean_ = np.mean(y) # function mean from numpy #mean_ print(mean_) #8.7 # #print(type(mean_)) #<class 'numpy.float64'> mean_ = y.mean() # method mean from numpy #mean_ print(mean_) #8.7 # #print(type(mean_)) #<class 'numpy.float64'> #The function mean() and method .mean() from NumPy return the same result as statistics.mean(). This is also the case when there are nan values among your data: #np.mean(y_with_nan) print(np.mean(y_with_nan)) #nan #y_with_nan.mean() print(y_with_nan.mean()) #nan #np.nanmean(y_with_nan) print(np.nanmean(y_with_nan)) #8.7 #nanmean() simply ignores all nan values. It returns the same value as mean() if you were to apply it to the dataset without the nan values. #pd.Series objects also have the method .mean(): mean_ = z.mean() #mean_ print(mean_) #8.7 #As you can see, it’s used similarly as in the case of NumPy. However, .mean() from Pandas ignores nan values by default: #z_with_nan.mean() print(z_with_nan.mean()) #8.7 # #option parameter "skipna" # #print(z_with_nan.mean(skipna=None)) #8.7 # #print(z_with_nan.mean(skipna=True)) #8.7 # #print(z_with_nan.mean(skipna=False)) #nan ### Weighted Mean #0.2 * 2 + 0.5 * 4 + 0.3 * 8 print(0.2 * 2 + 0.5 * 4 + 0.3 * 8) #4.8 x = [8.0, 1, 2.5, 4, 28.0] w = [0.1, 0.2, 0.3, 0.25, 0.15] print(sum(w)) # wmean = sum(w[i] * x[i] for i in range(len(x))) / sum(w) #wmean print(wmean) #6.95 # #wmean = sum(x_ * w_ for (x_, w_) in zip(x, w)) / sum(w) wmean = sum(w_ * x_ for (w_, x_) in zip(w, x)) / sum(w) #wmean print(wmean) #6.95 y, z, w = np.array(x), pd.Series(x), np.array(w) wmean = np.average(y, weights=w) #wmean print(wmean) #6.95 # wmean = np.average(z, weights=w) #wmean print(wmean) #6.95 # #The result is the same as in the case of the pure Python implementation. You can also use this method on ordinary lists and tuples. #(w * y).sum() / w.sum() print((w * y).sum() / w.sum()) #6.95 #However, be careful if your dataset contains nan values: # # w = np.array([0.1, 0.2, 0.3, 0.0, 0.2, 0.1]) #(w * y_with_nan).sum() / w.sum() print((w * y_with_nan).sum() / w.sum()) #nan # #np.average(y_with_nan, weights=w) print(np.average(y_with_nan, weights=w)) #nan # #np.average(z_with_nan, weights=w) print(np.average(z_with_nan, weights=w)) #nan #In this case, average() returns nan, which is consistent with np.mean(). ###Harmonic Mean hmean = len(x) / sum(1 / item for item in x) #hmean print(hmean) #2.7613412228796843 hmean = statistics.harmonic_mean(x) #hmean print(hmean) #2.7613412228796843 #statistics.harmonic_mean() #If you have a nan value in a dataset, then it’ll return nan. #If there’s at least one 0, then it’ll return 0. If you provide at least one negative number, then you’ll get statistics.StatisticsError: #statistics.harmonic_mean(x_with_nan) print(statistics.harmonic_mean(x_with_nan)) #nan #statistics.harmonic_mean([1, 0, 2]) print(statistics.harmonic_mean([1, 0, 2])) #0 #statistics.harmonic_mean([1, 2, -2]) # Raises StatisticsError #print(statistics.harmonic_mean([1, 2, -2]) # Raises StatisticsError) #scipy.stats.hmean(): #scipy.stats.hmean(y) print(scipy.stats.hmean(y)) #2.7613412228796843 #scipy.stats.hmean(z) print(scipy.stats.hmean(z)) #2.7613412228796843 #Again, this is a pretty straightforward implementation. However, if your dataset contains nan, 0, a negative number, or anything but positive numbers, then you’ll get a ValueError! # #print(scipy.stats.hmean(x_with_nan)) #print(scipy.stats.hmean([1, 0, 2])) #print(scipy.stats.hmean([1, 2, -2])) ###Geometric Mean gmean = 1 for item in x: gmean *= item gmean **= 1 / len(x) #gmean print(gmean) #4.677885674856041 #Python 3.8 introduced statistics.geometric_mean(), which converts all values to floating-point numbers and returns their geometric mean: gmean = statistics.geometric_mean(x) #gmean print(gmean) #4.67788567485604 gmean = statistics.geometric_mean(x_with_nan) #gmean print(gmean) #nan #scipy.stats.gmean(y) print(scipy.stats.gmean(y)) #4.67788567485604 #scipy.stats.gmean(z) print(scipy.stats.gmean(z)) #4.67788567485604 #print(scipy.stats.gmean(x_with_nan)) #nan #print(scipy.stats.gmean([1, 0, 2])) #0.0 (and warning) #print(scipy.stats.gmean([1, 2, -2])) #nan (and warning) ###Median #print(np.median([2, 4, 1, 8, 9])) #4.0 #print(np.median([2, 4, 1, 8])) #3.0 (=(2+4)/2) n = len(x) #1. Sorting the elements of the dataset #2. Finding the middle element(s) in the sorted dataset if n % 2: median_ = sorted(x)[round(0.5*(n-1))] else: x_ord, index = sorted(x), round(0.5 * n) median_ = 0.5 * (x_ord[index-1] + x_ord[index]) #median_ print(median_) #4 #statistics.median(): # #print(x) #[8.0, 1, 2.5, 4, 28.0] # median_ = statistics.median(x) #median_ print(median_) #4 median_ = statistics.median(x[:-1]) # #print(x[:-1]) #[8.0, 1, 2.5, 4] # #median_ print(median_) #3.25 (=(2.5+4)/2) #median_low() #median_high() #statistics.median_low(x[:-1]) print(statistics.median_low(x[:-1])) #2.5 # #statistics.median_high(x[:-1]) print(statistics.median_high(x[:-1])) #4 #Unlike most other functions from the Python statistics library, median(), median_low(), and median_high() don’t return nan when there are nan values among the data points: #print(x) #[8.0, 1, 2.5, 4, 28.0] # #print(sorted(x)) #[1, 2.5, 4, 8.0, 28.0] #print(x_with_nan) #[8.0, 1, 2.5, nan, 4, 28.0] #print(sorted(x_with_nan)) #[1, 2.5, 4, 8.0, nan, 28.0] #statistics.median(x) #print(statistics.median(x)) #4 #statistics.median(x_with_nan) print(statistics.median(x_with_nan)) #6.0 (=(4+8)/2) #statistics.median_low(x_with_nan) print(statistics.median_low(x_with_nan)) #4 #statistics.median_high(x_with_nan) print(statistics.median_high(x_with_nan)) #8.0 #np.median(): median_ = np.median(y) #median_ print(median_) #4.0 # median_ = np.median(y[:-1]) median_ print(median_) #3.25 #You’ve obtained the same values with statistics.median() and np.median(). # #However, if there’s a nan value in your dataset, then np.median() issues the RuntimeWarning and returns nan. If this behavior is not what you want, then you can use nanmedian() to ignore all nan values: #print(np.nanmedian(y)) #4.0 #print(np.nanmedian(y[:-1])) #3.25 #np.nanmedian(y_with_nan) print(np.nanmedian(y_with_nan)) #4.0 # #np.nanmedian(y_with_nan[:-1]) print(np.nanmedian(y_with_nan[:-1])) #3.25 #Pandas Series objects have the method .median() that ignores nan values by default: #print(z) #0 8.0 #1 1.0 #2 2.5 #3 4.0 #4 28.0 #dtype: float64 # #z.median() print(z.median()) #4.0 #print(z_with_nan) #0 8.0 #1 1.0 #2 2.5 #3 NaN #4 4.0 #5 28.0 #dtype: float64 # #z_with_nan.median() print(z_with_nan.median()) #4.0 #The behavior of .median() is consistent with .mean() in Pandas. You can change this behavior with the optional parameter skipna. ###Mode u = [2, 3, 2, 8, 12] print(u) mode_ = max((u.count(item), item) for item in set(u))[1] #mode_ print(mode_) #2 #u2 = [2, 3, 2, 8, 3] #print(u2) #mode_2 = max((u2.count(item), item) for item in set(u2))[1] ##mode_2 = ((u2.count(item), item) for item in set(u2))[1] #mode_2 #print(mode_2) #3 #statistics.mode() and statistics.multimode(): mode_ = statistics.mode(u) #mode_ print(mode_) #2 (a single value) mode_ = statistics.multimode(u) #mode_ print(mode_) #[2] (a list) # If there’s more than one modal value, then mode() raises StatisticsError, while multimode() returns the list with all modes: v = [12, 15, 12, 15, 21, 15, 12] print(v) #[12, 15, 12, 15, 21, 15, 12] # #statistics.mode(v) # Raises StatisticsError (incorrect description) print(statistics.mode(v)) #12 # no error # #statistics.multimode(v) print(statistics.multimode(v)) #[12, 15] #statistics.mode() and statistics.multimode() handle nan values as regular values and can return nan as the modal value: #statistics.mode([2, math.nan, 2]) print(statistics.mode([2, math.nan, 2])) #2 #statistics.multimode([2, math.nan, 2]) print(statistics.multimode([2, math.nan, 2])) #[2] #statistics.mode([2, math.nan, 0, math.nan, 5]) print(statistics.mode([2, math.nan, 0, math.nan, 5])) #nan #statistics.multimode([2, math.nan, 0, math.nan, 5]) print(statistics.multimode([2, math.nan, 0, math.nan, 5])) #[nan] #Note: statistics.multimode() is introduced in Python 3.8. #scipy.stats.mode(): # u, v = np.array(u), np.array(v) #print(v) #[12, 15, 12, 15, 21, 15, 12] #print(u) #[ 2 3 2 8 12] mode_ = scipy.stats.mode(u) #mode_ print(mode_) #ModeResult(mode=array([2]), count=array([2])) mode_ = scipy.stats.mode(v) #mode_ print(mode_) #ModeResult(mode=array([12]), count=array([3])) # #This function returns the object with the modal value and the number of times it occurs. If there are multiple modal values in the dataset, then only the smallest value is returned. #mode_.mode print(mode_.mode) #array([12]) # #mode_.count print(mode_.count) #array([3]) # #This code uses .mode to return the smallest mode (12) in the array v and .count to return the number of times it occurs (3). #scipy.stats.mode() is also flexible with nan values. It allows you to define desired behavior with the optional parameter nan_policy. This parameter can take on the values 'propagate', 'raise' (an error), or 'omit'. #Pandas Series objects have the method .mode() that handles multimodal values well and ignores nan values by default: #print(u) #[ 2 3 2 8 12] # #print(v) #[12, 15, 12, 15, 21, 15, 12] # #print(pd.Series([2, 2, math.nan])) #dtype: float64 #u, v, w = pd.Series(u), pd.Series(v), pd.Series([2, 2, math.nan]) #u.mode() #print(u.mode()) #0 2 #dtype: int64 #v.mode() #print(v.mode()) #0 12 #1 15 #dtype: int64 #w.mode() #print(w.mode()) #0 2.0 #dtype: float64 #As you can see, .mode() returns a new pd.Series that holds all modal values. If you want .mode() to take nan values into account, then just pass the optional argument dropna=False. ###Measures of Variability # # - Variance # - Standard deviation # - Skewness # - Percentiles # - Ranges # - Variance ###Variance #x = [8.0, 1, 2.5, 4, 28.0] #print(x) n = len(x) mean_ = sum(x) / n var_ = sum((item - mean_)**2 for item in x) / (n - 1) #var_ print(var_) #123.19999999999999 #statistics.variance(): var_ = statistics.variance(x) #var_ print(var_) #123.2 #You’ve obtained the same result for the variance as above. variance() can avoid calculating the mean if you provide the mean explicitly as the second argument: statistics.variance(x, mean_). #print(statistics.variance(x, statistics.fmean(x))) #123.2 #statistics.variance(x_with_nan) print(statistics.variance(x_with_nan)) #nan var_ = np.var(y, ddof=1) #var_ print(var_) #123.19999999999999 # var_ = y.var(ddof=1) #var_ print(var_) #123.19999999999999 # #ddof=1 : the delta degrees of freedom = 1 #This parameter allows the proper calculation of 𝑠², with (𝑛 − 1) in the denominator instead of 𝑛. #np.var(y_with_nan, ddof=1) print(np.var(y_with_nan, ddof=1)) #nan #y_with_nan.var(ddof=1) print(y_with_nan.var(ddof=1)) #nan #This is consistent with np.mean() and np.average(). If you want to skip nan values, then you should use np.nanvar(): #np.nanvar(y_with_nan, ddof=1) print(np.nanvar(y_with_nan, ddof=1)) #123.19999999999999 #np.nanvar() ignores nan values. It also needs you to specify ddof=1. #pd.Series objects have the method .var() that skips nan values by default: #z.var(ddof=1) print(z.var(ddof=1)) #123.19999999999999 # #print(z_with_nan) #0 8.0 #1 1.0 #2 2.5 #3 NaN #4 4.0 #5 28.0 #dtype: float64 # #z_with_nan.var(ddof=1) print(z_with_nan.var(ddof=1)) #123.19999999999999 #It also has the parameter ddof, but its default value is 1, so you can omit it. If you want a different behavior related to nan values, then use the optional parameter skipna. ##population variance # #You can get the population variance similar to the sample variance, with the following differences: # # - Replace (n - 1) with n in the pure Python implementation. # - Use statistics.pvariance() instead of statistics.variance(). # - Specify the parameter ddof=0 if you use NumPy or Pandas. In NumPy, you can omit ddof because its default value is 0. # #Note that you should always be aware of whether you’re working with a sample or the entire population whenever you’re calculating the variance! ### Standard Deviation std_ = var_ ** 0.5 #std_ print(std_) #11.099549540409285 #statistics.stdev(): std_ = statistics.stdev(x) #std_ print(std_) #11.099549540409287 #print(statistics.stdev(x, mean_)) #11.099549540409287 #NumPy #np.std(y, ddof=1) print(np.std(y, ddof=1)) #11.099549540409285 #y.std(ddof=1) print(y.std(ddof=1)) #11.099549540409285 #np.std(y_with_nan, ddof=1) print(np.std(y_with_nan, ddof=1)) #nan #y_with_nan.std(ddof=1) print(y_with_nan.std(ddof=1)) #nan #np.nanstd(y_with_nan, ddof=1) print(np.nanstd(y_with_nan, ddof=1)) #11.099549540409285 #Don’t forget to set the delta degrees of freedom to 1! #pandas # #pd.Series objects also have the method .std() that skips nan by default: #z.std(ddof=1) print(z.std(ddof=1)) #11.099549540409285 #z_with_nan.std(ddof=1) print(z_with_nan.std(ddof=1)) #11.099549540409285 #The parameter ddof defaults to 1, so you can omit it. Again, if you want to treat nan values differently, then apply the parameter skipna. #The population standard deviation refers to the entire population. It’s the positive square root of the population variance. You can calculate it just like the sample standard deviation, with the following differences: # # - Find the square root of the population variance in the pure Python implementation. # - Use statistics.pstdev() instead of statistics.stdev(). # - Specify the parameter ddof=0 if you use NumPy or Pandas. In NumPy, you can omit ddof because its default value is 0. # #As you can see, you can determine the standard deviation in Python, NumPy, and Pandas in almost the same way as you determine the variance. You use different but analogous functions and methods with the same arguments. ###Skewness x = [8.0, 1, 2.5, 4, 28.0] n = len(x) mean_ = sum(x) / n var_ = sum((item - mean_)**2 for item in x) / (n - 1) std_ = var_ ** 0.5 # #sample skewness skew_ = (sum((item - mean_)**3 for item in x) * n / ((n - 1) * (n - 2) * std_**3)) #skew_ print(skew_) #1.9470432273905929 #The skewness is positive, so x has a right-side tail. #scipy.stats.skew(): y, y_with_nan = np.array(x), np.array(x_with_nan) #scipy.stats.skew(y, bias=False) print(scipy.stats.skew(y, bias=False)) #1.9470432273905927 # #scipy.stats.skew(y_with_nan, bias=False) print(scipy.stats.skew(y_with_nan, bias=False)) #nan #The optional parameter nan_policy can take the values 'propagate', 'raise', or 'omit'. It allows you to control how you’ll handle nan values. #Pandas Series objects #have the method .skew() that also returns the skewness of a dataset: #z, z_with_nan = pd.Series(x), pd.Series(x_with_nan) # #z.skew() print(z.skew()) #1.9470432273905924 # #z_with_nan.skew() print(z_with_nan.skew()) #1.9470432273905924 ###Percentiles #The sample 𝑝 percentile is the element in the dataset such that 𝑝% of the elements in the dataset are less than or equal to that value. Also, (100 − 𝑝)% of the elements are greater than or equal to that value. #Each part has approximately the same number of items. If you want to divide your data into several intervals, then you can use #statistics.quantiles(): x = [-5.0, -1.1, 0.1, 2.0, 8.0, 12.8, 21.0, 25.8, 41.0] print(x) #print(sorted(x)) #statistics.quantiles(x, n=2) print(statistics.quantiles(x, n=2)) #[8.0] #print(statistics.quantiles(x, n=4)) #[-0.5, 8.0, 23.4] # #print((0.1 - (-1.1))/2 + (-1.1)) #-0.5 # #print((25.8 - 21.0)/2 + 21.0) #23.4 #print(-5.0 + (41 - (-5.0))/4 * 0) #-5.0 # #print(-5.0 + (41 - (-5.0))/4 * 1) #6.5 # #print(-5.0 + (41 - (-5.0))/4 * 2) #18.0 # #print(-5.0 + (41 - (-5.0))/4 * 3) #29.5 # #print(-5.0 + (41 - (-5.0))/4 * 4) #41.0 #statistics.quantiles(x, n=4, method='inclusive') print(statistics.quantiles(x, n=4, method='inclusive')) #[0.1, 8.0, 21.0] #Note: statistics.quantiles() is introduced in Python 3.8. #np.percentile() #x = [-5.0, -1.1, 0.1, 2.0, 8.0, 12.8, 21.0, 25.8, 41.0] y = np.array(x) #np.percentile(y, 5) #print(np.percentile(y, 0)) #-5.0 print(np.percentile(y, 5)) #-3.44 #np.percentile(y, 95) print(np.percentile(y, 95)) #34.919999999999995 #print(np.percentile(y, 100)) #41.0 #percentile() takes several arguments. You have to provide the dataset as the first argument and the percentile value as the second. The dataset can be in the form of a NumPy array, list, tuple, or similar data structure. The percentile can be a number between 0 and 100 like in the example above, but it can also be a sequence of numbers: #np.percentile(y, [25, 50, 75]) print(np.percentile(y, [25, 50, 75])) #array([ 0.1, 8. , 21. ]) # #np.median(y) print(np.median(y)) #8.0 #If you want to ignore nan values, then use #np.nanpercentile() #instead: y_with_nan = np.insert(y, 2, np.nan) #y_with_nan print(y_with_nan) #array([-5. , -1.1, nan, 0.1, 2. , 8. , 12.8, 21. , 25.8, 41. ]) #np.nanpercentile(y_with_nan, [25, 50, 75]) print(np.nanpercentile(y_with_nan, [25, 50, 75])) #array([ 0.1, 8. , 21. ]) #Numpy # #NumPy also offers you very similar functionality in quantile() and nanquantile(). If you use them, then you’ll need to provide the quantile values as the numbers between 0 and 1 instead of percentiles: #x = [-5.0, -1.1, 0.1, 2.0, 8.0, 12.8, 21.0, 25.8, 41.0] #np.quantile(y, 0.05) print(np.quantile(y, 0.05)) #-3.44 #np.quantile(y, 0.95) print(np.quantile(y, 0.95)) #34.919999999999995 #np.quantile(y, [0.25, 0.5, 0.75]) print(np.quantile(y, [0.25, 0.5, 0.75])) #array([ 0.1, 8. , 21. ]) #np.nanquantile(y_with_nan, [0.25, 0.5, 0.75]) print(np.nanquantile(y_with_nan, [0.25, 0.5, 0.75])) #array([ 0.1, 8. , 21. ]) #Pandas # #pd.Series objects have the method .quantile(): z, z_with_nan = pd.Series(y), pd.Series(y_with_nan) #z.quantile(0.05) print(z.quantile(0.05)) #-3.44 #z.quantile(0.95) print(z.quantile(0.95)) #34.919999999999995 #z.quantile([0.25, 0.5, 0.75]) print(z.quantile([0.25, 0.5, 0.75])) #0.25 0.1 #0.50 8.0 #0.75 21.0 #dtype: float64 #z_with_nan.quantile([0.25, 0.5, 0.75]) print(z_with_nan.quantile([0.25, 0.5, 0.75])) #0.25 0.1 #0.50 8.0 #0.75 21.0 #dtype: float64 ###Ranges #np.ptp(): #print(x) #x = [-5.0, -1.1, 0.1, 2.0, 8.0, 12.8, 21.0, 25.8, 41.0] # #y = np.array(x) #z, z_with_nan = pd.Series(y), pd.Series(y_with_nan) #print(type(x)) #<class 'list'> #print(type(y)) #<class 'numpy.ndarray'> #print(type(z)) #<class 'pandas.core.series.Series'> #np.ptp(y) print(np.ptp(y)) #46.0 (41.0 - (-5.0)) #np.ptp(z) print(np.ptp(z)) #46.0 #print(y_with_nan) #array([-5. , -1.1, nan, 0.1, 2. , 8. , 12.8, 21. , 25.8, 41. ]) # #np.ptp(y_with_nan) print(np.ptp(y_with_nan)) #nan #z, z_with_nan = pd.Series(y), pd.Series(y_with_nan) # #print(type(z_with_nan)) #<class 'pandas.core.series.Series'> # #np.ptp(z_with_nan) print(np.ptp(z_with_nan)) #46.0 (incorrect) #nan #Alternatively, you can use built-in Python, NumPy, or Pandas functions and methods to calculate the maxima and minima of sequences: # # - max() and min() from the Python standard library # - amax() and amin() from NumPy # - nanmax() and nanmin() from NumPy to ignore nan values # - .max() and .min() from NumPy # - .max() and .min() from Pandas to ignore nan values by default # #Here are some examples of how you would use these routines: #np.amax(y) - np.amin(y) print(np.amax(y) - np.amin(y)) #46.0 #np.nanmax(y_with_nan) - np.nanmin(y_with_nan) print(np.nanmax(y_with_nan) - np.nanmin(y_with_nan)) #46.0 #y.max() - y.min() print(y.max() - y.min()) #46.0 #z.max() - z.min() print(z.max() - z.min()) #46.0 #z_with_nan.max() - z_with_nan.min() print(z_with_nan.max() - z_with_nan.min()) #46.0 #print(y) #[-5. -1.1 0.1 2. 8. 12.8 21. 25.8 41. ] #print(np.quantile(y, [0.25, 0.50, 0.75])) #[ 0.1 8. 21. ] quartiles = np.quantile(y, [0.25, 0.75]) # #print(quartiles[0]) #0.1 # #print(quartiles[1]) #21.0 #quartiles[1] - quartiles[0] print(quartiles[1] - quartiles[0]) #20.9 quartiles = z.quantile([0.25, 0.75]) #print(quartiles) #0.25 0.1 #0.75 21.0 #dtype: float64 #quartiles[0.75] - quartiles[0.25] print(quartiles[0.75] - quartiles[0.25]) #20.9 #Note that you access the values in a Pandas Series object with the labels 0.75 and 0.25. #####Summary of Descriptive Statistics #SciPy and Pandas offer useful routines to quickly get descriptive statistics with a single function or method call. You can use #scipy.stats.describe() #like this: result = scipy.stats.describe(y, ddof=1, bias=False) #result print(result) #DescribeResult(nobs=9, minmax=(-5.0, 41.0), mean=11.622222222222222, variance=228.75194444444446, skewness=0.9249043136685094, kurtosis=0.14770623629658886) #describe() returns an object that holds the following descriptive statistics: # #nobs: the number of observations or elements in your dataset #minmax: the tuple with the minimum and maximum values of your dataset #mean: the mean of your dataset #variance: the variance of your dataset #skewness: the skewness of your dataset #kurtosis: the kurtosis of your dataset #You can access particular values with dot notation: #print(y) #[-5. -1.1 0.1 2. 8. 12.8 21. 25.8 41. ] #result.nobs print(result.nobs) #9 #result.minmax[0] # Min print(result.minmax[0]) #-5.0 #result.minmax[1] # Max print(result.minmax[1]) #41.0 #result.mean print(result.mean) #11.622222222222222 #result.variance print(result.variance) #228.75194444444446 #result.skewness print(result.skewness) #0.9249043136685094 #result.kurtosis print(result.kurtosis) #0.14770623629658886 #With SciPy, you’re just one function call away from a descriptive statistics summary for your dataset. # #Pandas has similar, if not better, functionality. Series objects have the method .describe(): #print(type(result)) #<class 'scipy.stats.stats.DescribeResult'> result = z.describe() #result print(result) #count 9.000000 #mean 11.622222 #std 15.124548 #min -5.000000 #25% 0.100000 #50% 8.000000 #75% 21.000000 #max 41.000000 #dtype: float64 #It returns a new Series that holds the following: # # - count: the number of elements in your dataset # - mean: the mean of your dataset # - std: the standard deviation of your dataset # - min and max: the minimum and maximum values of your dataset # - 25%, 50%, and 75%: the quartiles of your dataset #result['mean'] print(result['mean']) #11.622222222222222 # #result['std'] print(result['std']) #15.12454774346805 # print(result['min']) #-5.0 # #result['max'] print(result['max']) #41.0 # #result['25%'] print(result['25%']) #0.1 # #result['50%'] print(result['50%']) #8.0 # #result['75%'] print(result['75%']) #21.0 ###Measures of Correlation Between Pairs of Data #Note: There’s one important thing you should always have in mind when working with correlation among a pair of variables, and that’s that correlation is not a measure or indicator of causation, but only of association! x = list(range(-10, 11)) y = [0, 2, 2, 2, 2, 3, 3, 6, 7, 4, 7, 6, 6, 9, 4, 5, 5, 10, 11, 12, 14] x_, y_ = np.array(x), np.array(y) x__, y__ = pd.Series(x_), pd.Series(y_) ''' df = pd.concat([x__, y__], axis=1, join='inner') df = df.rename(columns={0: 'x__', 1: 'y__'}) print(df) df.plot( kind="scatter", x=0, y=1 ) import matplotlib.pyplot as plt plt.show() ''' ###Covariance n = len(x) mean_x, mean_y = sum(x) / n, sum(y) / n cov_xy = (sum((x[k] - mean_x) * (y[k] - mean_y) for k in range(n)) / (n - 1)) cov_xy print(cov_xy) #19.95 #NumPy cov_matrix = np.cov(x_, y_) #cov_matrix print(cov_matrix) #array([[38.5 , 19.95 ], # [19.95 , 13.91428571]]) # #bias = (default) False #ddof = (default) None #x_.var(ddof=1) print(x_.var(ddof=1)) #38.5 #y_.var(ddof=1) print(y_.var(ddof=1)) #13.914285714285711 cov_xy = cov_matrix[0, 1] #cov_xy print(cov_xy) #19.95 # cov_xy = cov_matrix[1, 0] #cov_xy print(cov_xy) #19.95 #Pandas Series have the method .cov() that you can use to calculate the covariance: cov_xy = x__.cov(y__) #cov_xy print(cov_xy) #19.95 cov_xy = y__.cov(x__) #cov_xy print(cov_xy) #19.95 ###Correlation Coefficient var_x = sum((item - mean_x)**2 for item in x) / (n - 1) var_y = sum((item - mean_y)**2 for item in y) / (n - 1) std_x, std_y = var_x ** 0.5, var_y ** 0.5 r = cov_xy / (std_x * std_y) #r print(r) #0.861950005631606 #scipy.stats # has the routine pearsonr() that calculates the correlation coefficient and the 𝑝-value: r, p = scipy.stats.pearsonr(x_, y_) #r print(r) #0.861950005631606 # #p print(p) #5.122760847201171e-07 #numpy #np.corrcoef() corr_matrix = np.corrcoef(x_, y_) #corr_matrix print(corr_matrix) #array([[1. , 0.86195001], # [0.86195001, 1. ]]) r = corr_matrix[0, 1] #r print(r) #0.8619500056316061 r = corr_matrix[1, 0] #r print(r) #0.861950005631606 #scipy # #Liner Regression #scipy.stats.linregress() # #scipy.stats.linregress(x_, y_) print(scipy.stats.linregress(x_, y_)) #LinregressResult(slope=0.5181818181818181, intercept=5.714285714285714, rvalue=0.861950005631606, pvalue=5.122760847201164e-07, stderr=0.06992387660074979) result = scipy.stats.linregress(x_, y_) r = result.rvalue #r print(r) #0.861950005631606 #Pandas r = x__.corr(y__) #r print(r) #0.8619500056316061 r = y__.corr(x__) #r print(r) #0.861950005631606 #####Working With 2D Data ###Axes a = np.array([[1, 1, 1], [2, 3, 1], [4, 9, 2], [8, 27, 4], [16, 1, 1]]) #a #print(a) #[[ 1 1 1] # [ 2 3 1] # [ 4 9 2] # [ 8 27 4] # [16 1 1]] #np.mean(a) print(np.mean(a)) #5.4 #a.mean() print(a.mean()) #5.4 #np.median(a) print(np.median(a)) #2.0 #a.var(ddof=1) print(a.var(ddof=1)) #53.40000000000001 #parameter axis # #axis=None says to calculate the statistics across all data in the array. The examples above work like this. This behavior is often the default in NumPy. #axis=0 says to calculate the statistics across all rows, that is, for each column of the array. This behavior is often the default for SciPy statistical functions. #axis=1 says to calculate the statistics across all columns, that is, for each row of the array. #np.mean(a, axis=0) print(np.mean(a, axis=0)) #[6.2, 8.2, 1.8] #a.mean(axis=0) print(a.mean(axis=0)) #[6.2, 8.2, 1.8] #np.mean(a, axis=1) print(np.mean(a, axis=1)) #[ 1. 2. 5. 13. 6.] #a.mean(axis=1) print(a.mean(axis=1)) #[ 1. 2. 5. 13. 6.] #np.median(a, axis=0) print(np.median(a, axis=0)) #[4., 3., 1.] #np.median(a, axis=1) print(np.median(a, axis=1)) #[1., 2., 4., 8., 1.] #a.var(axis=0, ddof=1) print(a.var(axis=0, ddof=1)) #[ 37.2, 121.2, 1.7] #a.var(axis=1, ddof=1) print(a.var(axis=1, ddof=1)) #[ 0. 1. 13. 151. 75.] #SciPy #scipy.stats.gmean(a) # Default: axis=0 print(scipy.stats.gmean(a)) #array([4. , 3.73719282, 1.51571657]) #scipy.stats.gmean(a, axis=0) print(scipy.stats.gmean(a, axis=0)) #array([4. , 3.73719282, 1.51571657]) #scipy.stats.gmean(a, axis=1) print(scipy.stats.gmean(a, axis=1)) #[1. 1.81712059 4.16016765 9.52440631 2.5198421 ] ###DataFrames row_names = ['first', 'second', 'third', 'fourth', 'fifth'] col_names = ['A', 'B', 'C'] df = pd.DataFrame(a, index=row_names, columns=col_names) #df print(df) # A B C #first 1 1 1 #second 2 3 1 #third 4 9 2 #fourth 8 27 4 #fifth 16 1 1 #df.mean() print(df.mean()) #A 6.2 #B 8.2 #C 1.8 #dtype: float64 # #df.var() print(df.var()) #A 37.2 #B 121.2 #C 1.7 #dtype: float64 #If you want the results for each row, then just specify the parameter axis=1: # #df.mean(axis=1) print(df.mean(axis=1)) #first 1.0 #second 2.0 #third 5.0 #fourth 13.0 #fifth 6.0 #dtype: float64 # #df.var(axis=1) print(df.var(axis=1)) #first 0.0 #second 1.0 #third 13.0 #fourth 151.0 #fifth 75.0 #dtype: float64 #df['A'] print(df['A']) #first 1 #second 2 #third 4 #fourth 8 #fifth 16 #Name: A, dtype: int64 #df['A'].mean() print(df['A'].mean()) #6.2 #df['A'].var() print(df['A'].var()) #37.20000000000001 #df.values print(df.values) #[[ 1 1 1] # [ 2 3 1] # [ 4 9 2] # [ 8 27 4] # [16 1 1]] #df.to_numpy() print(df.to_numpy()) #[[ 1 1 1] # [ 2 3 1] # [ 4 9 2] # [ 8 27 4] # [16 1 1]] #df.values and df.to_numpy() give you a NumPy array with all items from the DataFrame without row and column labels. Note that df.to_numpy() is more flexible because you can specify the data type of items and whether you want to use the existing data or copy it. #Like Series, DataFrame objects have the method .describe() that returns another DataFrame with the statistics summary for all columns: #df.describe() print(df.describe()) # A B C #count 5.00000 5.000000 5.00000 #mean 6.20000 8.200000 1.80000 #std 6.09918 11.009087 1.30384 #min 1.00000 1.000000 1.00000 #25% 2.00000 1.000000 1.00000 #50% 4.00000 3.000000 1.00000 #75% 8.00000 9.000000 2.00000 #max 16.00000 27.000000 4.00000 #df.describe().at['mean', 'A'] print(df.describe().at['mean', 'A']) #6.2 #df.describe().at['50%', 'B'] print(df.describe().at['50%', 'B']) #3.0 #####Visualizing Data #graphs: # # - Box plots # - Histograms # - Pie charts # - Bar charts # - X-Y plots # - Heatmaps import matplotlib.pyplot as plt plt.style.use('ggplot') #The module np.random generates arrays of pseudo-random numbers: # # - Normally distributed numbers are generated with np.random.randn(). # - Uniformly distributed integers are generated with np.random.randint(). ###Box Plots np.random.seed(seed=0) #if you don’t specify this value, then you’ll get different results each time x = np.random.randn(1000) y = np.random.randn(100) z = np.random.randn(10) fig, ax = plt.subplots() ax.boxplot((x, y, z), vert=False, showmeans=True, meanline=True, labels=('x', 'y', 'z'), patch_artist=True, medianprops={'linewidth': 2, 'color': 'purple'}, meanprops={'linewidth': 2, 'color': 'red'}) #The parameters of .boxplot() define the following: # # - x is your data. # - vert sets the plot orientation to horizontal when False. The default orientation is vertical (True). # - showmeans shows the mean of your data when True. # - meanline represents the mean as a line when True. The default representation is a point. # - labels: the labels of your data. # - patch_artist determines how to draw the graph. # - medianprops denotes the properties of the line representing the median. # - meanprops indicates the properties of the line or dot representing the mean. plt.savefig("Figure_1_Box_Plot.png") # added to save a figure plt.show() #You can see three box plots. Each of them corresponds to a single dataset (x, y, or z) and show the following: # # - The mean is the red dashed line. # - The median is the purple line. # - The first quartile is the left edge of the blue rectangle. # - The third quartile is the right edge of the blue rectangle. # - The interquartile range is the length of the blue rectangle. # - The range contains everything from left to right. # - The outliers are the dots to the left and right. ###Histograms #np.histogram() hist, bin_edges = np.histogram(x, bins=10) #hist print(hist) #[ 9 20 70 146 217 239 160 86 38 15] #bin_edges print(bin_edges) #[-3.04614305 -2.46559324 -1.88504342 -1.3044936 -0.72394379 -0.14339397 # 0.43715585 1.01770566 1.59825548 2.1788053 2.75935511] # 1. hist contains the frequency or the number of items corresponding to each bin. # 2. bin_edges contains the edges or bounds of the bin. #What histogram() calculates, .hist() can show graphically: # fig, ax = plt.subplots() ax.hist(x, bin_edges, cumulative=False) ax.set_xlabel('x') ax.set_ylabel('Frequency') plt.savefig("Figure_2a_Histogram.png") # added to save a figure plt.show() #The first argument of .hist() is the sequence with your data. The second argument defines the edges of the bins. The third disables the option to create a histogram with cumulative values. #You can see the bin edges on the horizontal axis and the frequencies on the vertical axis. fig, ax = plt.subplots() ax.hist(x, bin_edges, cumulative=True) #cumulative ax.set_xlabel('x') ax.set_ylabel('Frequency') plt.savefig("Figure_2b_Histogram_cumulative.png") # added to save a figure plt.show() #You can also directly draw a histogram with pd.Series.hist() using matplotlib in the background. ###Pie Charts x, y, z = 128, 256, 1024 #matplotlib.axes.Axes.pie #.pie(): fig, ax = plt.subplots() ax.pie((x, y, z), labels=('x', 'y', 'z'), autopct='%1.1f%%') plt.savefig("Figure_3_Pie_Chart.png") # added to save a figure plt.show() #The first argument of .pie() is your data, and the second is the sequence of the corresponding labels. autopct defines the format of the relative frequencies shown on the figure. ###Bar Charts x = np.arange(21) y = np.random.randint(21, size=21) err = np.random.randn(21) #You can create a bar chart with .bar() if you want vertical bars or .barh() if you’d like horizontal bars: #fig, ax = plt.subplots()) fig, ax = plt.subplots() ax.bar(x, y, yerr=err) ax.set_xlabel('x') ax.set_ylabel('y') plt.savefig("Figure_4_Bar_Chart.png") # added to save a figure plt.show() #The heights of the red bars correspond to the frequencies y, while the lengths of the black lines show the errors err. If you don’t want to include the errors, then omit the parameter yerr of .bar(). ###X-Y Plots (scatter plot) #Let’s generate two datasets and perform linear regression with scipy.stats.linregress(): x = np.arange(21) y = 5 + 2 * x + 2 * np.random.randn(21) slope, intercept, r, *__ = scipy.stats.linregress(x, y) line = f'Regression line: y={intercept:.2f}+{slope:.2f}x, r={r:.2f}' #matplotlib.axes.Axes.plot #.plot() fig, ax = plt.subplots() ax.plot(x, y, linewidth=0, marker='s', label='Data points') ax.plot(x, intercept + slope * x, label=line) ax.set_xlabel('x') ax.set_ylabel('y') ax.legend(facecolor='white') plt.savefig("Figure_5_Scatter_Plot.png") # added to save a figure plt.show() ###Heatmaps #matplotlib.axes.Axes.imshow #.imshow(): #covariance matrix matrix = np.cov(x, y).round(decimals=2) fig, ax = plt.subplots() ax.imshow(matrix) ax.grid(False) ax.xaxis.set(ticks=(0, 1), ticklabels=('x', 'y')) ax.yaxis.set(ticks=(0, 1), ticklabels=('x', 'y')) ax.set_ylim(1.5, -0.5) for i in range(2): for j in range(2): ax.text(j, i, matrix[i, j], ha='center', va='center', color='w') plt.savefig("Figure_6a_Heatmap_covariance.png") # added to save a figure plt.show() #correlation coefficient matrix matrix = np.corrcoef(x, y).round(decimals=2) fig, ax = plt.subplots() ax.imshow(matrix) ax.grid(False) ax.xaxis.set(ticks=(0, 1), ticklabels=('x', 'y')) ax.yaxis.set(ticks=(0, 1), ticklabels=('x', 'y')) ax.set_ylim(1.5, -0.5) for i in range(2): for j in range(2): ax.text(j, i, matrix[i, j], ha='center', va='center', color='w') plt.savefig("Figure_6b_Heatmap_correlation.png") # added to save a figure plt.show() #####Conclusion ''' - Use Python’s statistics for the most important Python statistics functions. - Use NumPy to handle arrays efficiently. - Use SciPy for additional Python statistics routines for NumPy arrays. - Use Pandas to work with labeled datasets. - Use Matplotlib to visualize data with plots, charts, and histograms. In the era of big data and artificial intelligence, you must know how to calculate descriptive statistics measures. Now you’re ready to dive deeper into the world of data science and machine learning! If you have questions or comments, then please put them in the comments section below.''' |
Figures








Reference
by Mirko Stojiljkovic
https://realpython.com/python-statistics/

No comments:
Post a Comment